




Robots.txt for SEO: The Ultimate Guide

There are times when you must stop Google from crawling your site.
And the way you do this is by creating a tiny little file called a robots.txt file.
But don’t let its size fool you; when used correctly, it could boost your SEO.
If you use it wrong, your content might never see the light of day.
In this post, we’ll get into:
- What robots.txt means
- When you should use a robots.txt file
- How to create a robots.txt file
- Some examples of robots.txt files
What is a robots.txt file?
A robots.txt file, typically situated in a website’s root directory, instructs web crawlers which pages should be excluded from crawling or indexing. This file is crucial for managing search engine access, preventing content from being indexed to maintain privacy, controlling bandwidth usage, or focusing search engine attention on important areas of the site.
The robots.txt file is part of a group of web standards called the Robots Exclusion Protocol (REP) that regulate how web bots crawl the web to index content.
An example of a Robots.txt file
User-agent: *
Disallow: /private/
Disallow: /restricted-page.html
Disallow: /images/
Allow: /images/public/
In this example:
- User-agent: * is a wildcard that applies the rules to all web crawlers or robots.
- Disallow: specifies the directories or files that should not be crawled. For example, the /private/ directory and the /restricted-page.html file are off-limits.
- Allow is used to override a Disallow rule. In this case, while the entire /images/ directory is disallowed, the /images/public/ subdirectory is allowed.
How to find a robots.txt file
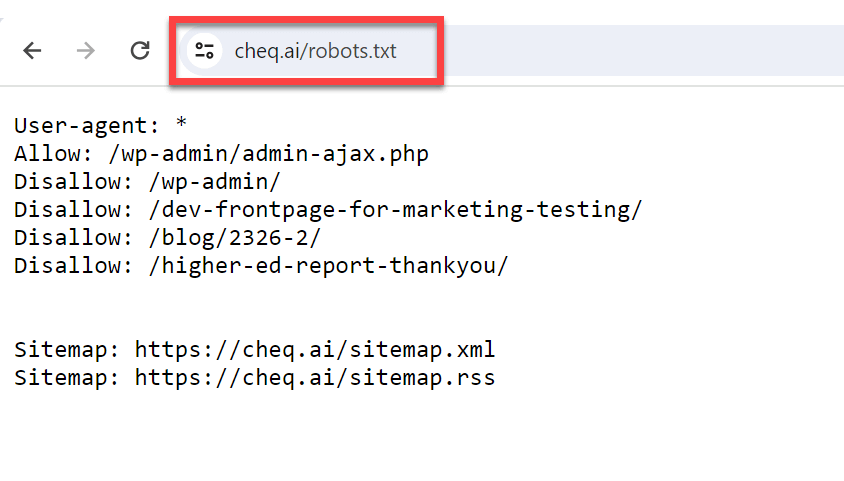
Finding a site’s robots.txt file is simple. You can usually see it by typing the URL for the homepage of a site and adding “/robots.txt.”
For example:
https://example.com/robots.txt
Why do you need a robots.txt file?
In general, you should review your robots.txt files as part of a comprehensive site audit. But your site might not need a robots.txt file. Without one, the Google bot will crawl through your entire site. This is exactly what you want it to do if you want your entire site to be indexed. You only need one if you want more control over what search engines crawl.
Here are the main scenarios in which you will need a robots.txt file:
1. Crawl budget optimization
Each website has a crawl budget. This means in a given time frame, Google will crawl a limited amount of pages on a site.
If the amount of pages on your site exceeds the crawl budget, you’ll have pages that don’t make it into Google’s index. And when your pages are not in Google’s index, there is very little chance of them ranking in search.
One easy way to optimize this is to make sure that search engine bots don’t crawl low-priority or non-essential content that doesn’t need frequent crawling. This could include duplicate pages, archives, or dynamically generated content that doesn’t significantly impact search rankings. This will save your crawl budget for the pages you do want indexed.
You can easily monitor nonessential sections of your site by setting up site segment analysis using Similarweb’s Website Segments tool. This will show you if those pages are getting indexed. Simply set up a segment that covers all your content. You can choose any rule, including:
- Folders
- Any variation of text
- Exact text
- Exact URLs
Below, we are setting up a segment for the /gp/ subfolder on amazon.com.

Once your segment is set up, go to the Marketing Channels report and look at Organic Traffic. This will quickly show you if this site segment is getting traffic and eating up your crawl budget. Below, you can see that the segment we are tracking is getting 491.6K visits over the period of one year.

2. Avoiding duplicate content issues
For many sites, duplicate content is unavoidable. For instance, if you are running an ecommerce site and you have multiple product pages that could potentially rank on a single keyword. Robots.txt is an easy way to avoid this.
3. Prioritizing important content
By using the Allow: directive, you can explicitly permit search engines to crawl and index specific high-priority content on your site. This helps ensure that important pages are discovered and indexed.
4. Preventing indexing of admin or test areas
If your site has admin or test areas that should not be indexed, using Disallow: in the robots.txt file can help prevent search engines from including these areas in search results.
How does robots.txt work?
Robots.txt files inform search engine bots what pages to ignore and which pages to prioritize. To understand this, let’s first explore what bots do.
How search engine bots discover and index content
The job of a search engine is to make web content available to end users through search. To do this, search engine bots or spiders have to discover content by systematically visiting and analyzing web pages. This process is called crawling.
To discover information, search engine bots start by visiting a list of known web pages. They then follow links from one page to another across the net.

Once a page is crawled, the information is parsed, and relevant data is stored in the search engine’s index. The index is a massive database that allows the search engine to quickly retrieve and display relevant results when a user performs a search query.
How do robots.txt files impact crawling and indexing?
When a bot lands on a site, it checks for a robots.txt file to determine how it should crawl and index the site. If the file is present, it provides instructions for crawling. If there’s no robots.txt file or it lacks crawling instructions, the bot will proceed to crawl the site.
The robots.txt file starts by specifying the user agent. A user agent refers to software that accesses web content, in our case, a search engine bot. It also includes directives such as
- Allow:
- Disallow:
For example:
User-agent: *
Disallow: /private/
Allow: /public/
Disallow: /restricted/
In this example:
- User-agent: * applies the rules to all web crawlers.
- Disallow: /private/ instructs all web crawlers to avoid crawling the /private/ directory.
- Allow: /public/ allows all web crawlers to crawl the /public/ directory, even though there is a broader Disallow directive.
- Disallow: /restricted/ further disallows crawling of the /restricted/ directory.
It’s important to note that robots.txt files are directives that search engine bots will generally follow. But if there are links pointing to a page that is disallowed, Google will still crawl that page and is likely to index it.
To avoid this, you should use noindex in the <head> section of the page’s HTML.
<meta name=”robots” content=”noindex”>
Implementing crawl directives: Understanding robots.txt syntax
A robots.txt file informs a search engine how to crawl by use of directives. A directive is a command that provides a system (in this case, a search engine bot) information on how to behave.
Each directive begins by first specifying the user-agent and then setting the rules for that user-agent. The user agent refers to the application that acts on behalf of a user when interacting with a system or network. In our case, the user agent refers to the web browser.
For example:
- User-agent: Googlebot
- User-agent: Bingbot
Below, we have compiled two lists; one contains supported directives and the other unsupported directives.
Supported Directives
Disallow: This directive prevents search engines from crawling certain areas of a website. You can:
- Block access to all directories for all user agents.
user-agent: * (The ‘*’ is a wild card. See below.)
Disallow: / - Block a particular directory for all user agents.
user-agent: *
Disallow: /portfolio - Block access to a PDF or any other files for all user agents using the appropriate file extension.
user-agent: *
Disallow: *.pdf
Allow: This directive allows search engines to crawl a page or directory. Use this directive to override a disallowed directive. Below we are blocking search engines from crawling the /portfolio folder but allowing them access to the /allowed-portfolio subfolder in the /portfolio folder.
user-agent: *
Disallow: /portfolio
Allow: /portfolio/allowed-portfolio
Sitemap: You can specify the location of your sitemap in your robots.txt file. A sitemap is a file on your site that provides a structured list of URLs to assist search engines in how to crawl your site.
Sitemap: https://www.example.com/sitemap.xml
If you want to understand more about directives, check out Google’s robots.txt guide.
Unsupported Directives
In 2019, Google posted that crawl-delay, nofollow, and noindex are not supported in robots.txt files. If you include them in your robots.txt files, they simply will not work. In reality, these rules were never supported by Google and were not intended to appear in robots.txt files but can be included in the robots’ meta tags on separate pages on your site.
There are other options if you want to exclude pages from Google’s index, including:
- Using the meta tag with noindex:
Add the following HTML meta tag to the <head> section of the page’s HTML:
<meta name=”robots” content=”noindex”>
- Using X-Robots-Tag HTTP header:
If you have access to server configuration, you can use the X-Robots-Tag HTTP header to achieve a similar result.
For example:
X-Robots-Tag: noindex
- Using Google Search Console:
You can use the URL Removal Tool to request the removal of a specific URL from Google’s index.
Since crawl-delay is not supported by Google, if you want to ask Google to crawl slower, you can set the crawl rate in Google Search Console.
Using wildcards
Wildcards are characters you can use to provide directives that apply to multiple URLs at once. The two main wildcards used in robots.txt files are the asterisk (*) and the dollar sign ($).
You can use them to apply directives or to user agents.
For example:
- Asterix (*): When applied to user agents, the wild card means “apply to all user agents.” When applied to URLs, it means “apply to all URLs.” If you have URLs that follow the same pattern, this will save you time.
- Dollar sign ($): The dollar sign is used at the end of a URL pattern to match URLs that end with a specific string.
User-agent: *
Disallow: /*.pdf$
In the example below, we are blocking search engines from crawling all PDF files.
user-agent: *
Disallow: /*.pdf$
URLs that end with .pdf will not be accessible. But take note that if your URL has additional text after the .pdf ending, then that URL will be accessible.
How to create robots.txt files
If your website doesn’t have a robots.txt file, you can easily create one in a text editor. Simply open a blank .txt document and insert your directives. When you are finished, just save the file as ‘robots.txt,’ and there you have it.
Now, you might be wondering where to put your robots.txt file.
In theory, you can put it in any main directory on your site, but to ensure that bots find it, we recommend uploading it to your root directory.
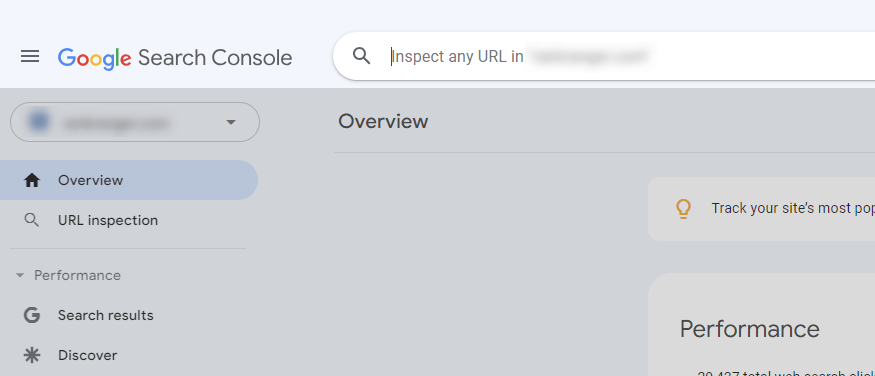
Next, upload it to the root directory of your website. Make sure it is accessible via a web browser at the path https://www.yourdomain.com/robots.txt. If you want to test how effective your robots.txt file is you can test any URL with the Google Search Console URL Inspection tool.
How to add robots.txt to WordPress
If you use WordPress, the easiest way to create a robots.txt file in WordPress is to use plugins like Yoast and All in One SEO Pack.
If you use Yoast, go to SEO > Tools > File Editor. Click on the robots.txt tab, and you can create or edit your robots.txt file there.
If you use All in One SEO Pack, go to One SEO > Feature Manager. Activate the “Robots.txt” feature, and you can configure your directives from there.
Common mistakes you want to avoid
Although there are many benefits to using robot.txt, getting them wrong can kill your traffic. Let’s get into some mistakes to avoid.
- Blocking important content: By using overly restrictive rules, you might accidentally restrict important sections of your site
- Blocking CSS, JavaScript, and Image files: Some search engines use these resources to understand the structure of your site
- Incorrect case sensitivity: Robots.txt files are case sensitive
- Assuming security through robots.txt: Sensitive content should be protected by other means as robots.txt is a guideline but does not ensure that pages will not be indexed
- Incorrect syntax: Validate your files as typos can lead to search engines misinterpreting your robots.txt files
Robots.txt files: The final word
You now have a comprehensive understanding of robots.txt files. You know what they are, how they work, and how they can be used to enhance your SEO. Just remember always to review and test your robots.txt files. Done right, they will serve you well; done wrong they might just mean the end of your organic traffic.
Use them wisely.
FAQs
What is the robots.txt file?
Robots.txt is a text file located in the root directory of a site and is used to inform web crawlers how to crawl and index the site.
How do I access a robots.txt file?
The easiest way to access a robots.txt file is to type the site’s URL into your browser and then add /robots.txt to the end. It should look like this: https://www.example.com/robots.txt.
Is robots.txt good for SEO?
The robots.txt file plays an important role in SEO. Although they don’t directly impact a website’s rankings, they help search engines understand the site’s structure and which pages to include or exclude from their index.
The robots.txt file can contribute to SEO by:
- Controlling Crawling
- Preserving Crawl Budgets
- Managing Sitemaps
- Preventing Indexation of Duplicate Content
It’s important to note that robots.txt files should be used carefully. Incorrectly configuring the file can inadvertently block search engines from accessing important content, leading to a negative impact on your site’s visibility.
When should you use a robots.txt file?
Use a robots.txt file to control search engine crawling. Restrict sensitive areas, prevent indexing of duplicate content, manage crawl budget, and guide bots away from non-essential or private content.

Related Posts


Generative AI Statistics for 2026: The Latest Trends & Data Insights

How I automated GEO keyword research with Claude and the Similarweb MCP


How Query Reformulation In LLMs Changes Keyword Research Methodology For GEO


Track Gen-AI And Organic KPI's On The #1 SEO Platform
Give it a try or talk to our marketing team - it’s free!