




What Are Noindex Tags, and How Do They Affect Your SEO?

The noindex meta tag gives website owners precise control over which pages appear in search results. By strategically using this directive, you can keep search engines from indexing pages that don’t serve your visitors – like duplicate content, administrative sections, or temporary landing pages.
In this guide, we’ll explore when and how to implement noindex tags to strengthen your site’s search presence and help search engines focus on your most valuable content.
What is a noindex tag?
A noindex tag tells search engines not to include a specific webpage in their search results. When you add this HTML directive to a page, search engines will still find and scan the content, but they won’t display it to users in search results – even if other websites link to that page.

Unlike robots.txt, which blocks search engines from accessing pages entirely, noindex tags offer more precise control over your content’s visibility in search results. You can implement noindex tags in two ways: through HTML meta tags in your page’s code or via HTTP response headers.
Here’s what a noindex HTML tag looks like:
<meta name="robots" content="noindex">
For non-HTML resources, you use the X-Robots-Tag HTTP header:
<x-robots-tag: noindex>
Understanding how noindex tags work is essential for ensuring that they are used correctly. Getting it wrong could result in important pages not being indexed.
Why is a noindex tag important in SEO?
These are the top reasons why noindex tags can help your website’s SEO efforts:

Quality control
Noindex tags help maintain your site’s authority by removing low-quality or shallow content from search results. You can hide outdated blog posts or irrelevant news articles that no longer align with your brand message. While deleting pages and implementing 301 redirects is typically the best practice, noindex tags provide a practical alternative when content removal isn’t feasible.
Managing crawl budget
By implementing noindex tags, you help search engines focus their resources on your most valuable pages. This is especially important for large websites where complete crawling might be impractical. The strategy preserves server resources and ensures search engines prioritize indexing your most critical content rather than spending time on less important pages.
Avoiding duplicate content
Noindex tags work alongside canonical tags to effectively manage similar content across your site. This prevents potential SEO penalties from duplicate pages and helps search engines understand which version of similar content to display in results. This is particularly useful for managing product pages that may have similar content but different URLs, ensuring only the primary version appears in search results.
When should I use a noindex meta tag?
Noindex tags are valuable tools for managing both individual pages and entire sections of your website in search results. Here are the key scenarios where implementing noindex tags makes sense:
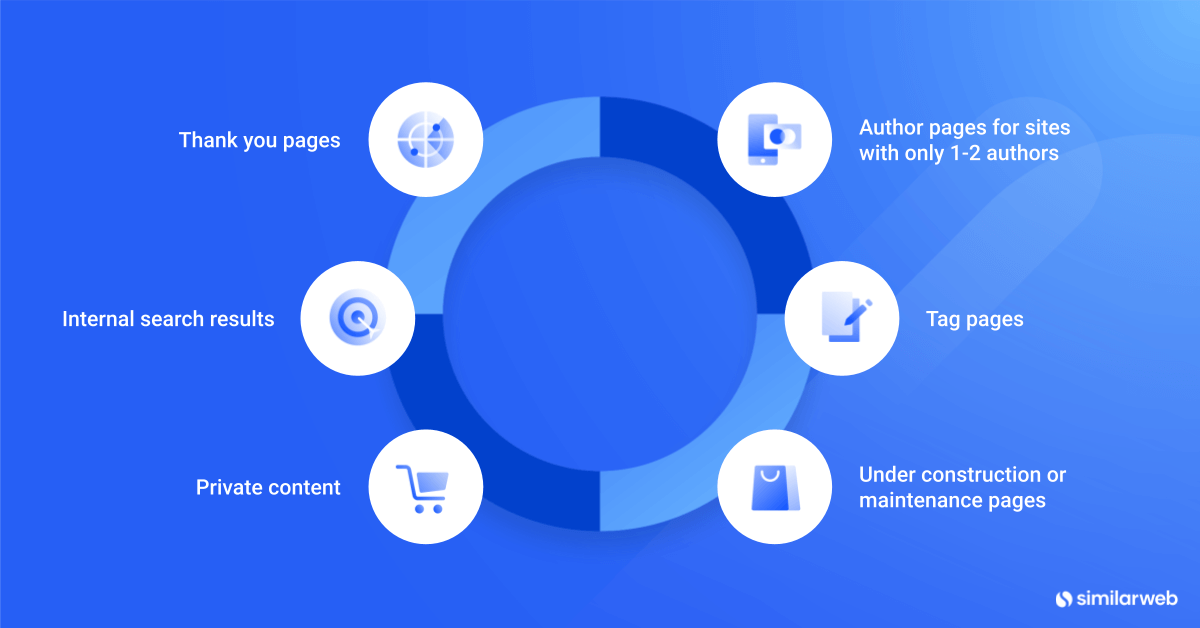
1. Thank you pages
Thank you pages typically contain no meaningful content for search users. Adding noindex tags to these pages prevents them from appearing in search results, where they would only create unnecessary clutter.
2. Internal search results
Your website’s search results pages can generate countless low-value URLs. Applying noindex tags to these pages prevents search engines from indexing automated results pages, which helps preserve your crawl budget and avoid duplicate content issues.
3. Private content
For membership areas, subscriber-only content, or other restricted sections, noindex tags help maintain privacy while keeping search results clean. This ensures private content remains hidden from public search results while still being accessible to authorized users.
4. Author pages for sites with only 1-2 authors
For websites with only one or two contributors, author pages often mirror the content of your homepage. In these cases, using noindex prevents duplicate content issues. However, for multi-author sites, keeping author pages indexed can provide value through unique biographical content and post collections.
5. Tag pages
When tag pages consist primarily of link lists with minimal unique content (such as posts tagged “Greek mythology”), they may not provide value to search users. Adding noindex tags to thin tag pages helps maintain your site’s overall search quality and prevents potential SEO issues.
6. Under construction or maintenance pages
Temporary pages, maintenance notices, and in-progress content should be kept out of search results. Using noindex tags on these pages ensures visitors only find your complete, polished content while preserving your crawl budget for active pages.
Should every ”noindex” page be ‘nofollow’ too?
No – these directives serve different purposes. While noindex prevents a page from appearing in search results, nofollow controls whether search engines should follow the page’s links. You can use either directive independently based on your needs.
When should you use both directives?
For pages with no meaningful content (like thank-you pages), using both noindex and nofollow makes sense:
<meta name="robots" content="noindex, nofollow">
When should you use only noindex?
If your page contains valuable outbound links that support your SEO strategy, use noindex alone:
<meta name="robots" content="noindex, follow">
How to implement noindex tags
It greatly depends on your CMS, and it’s a choice between meta robots noindex. Here are two common approaches to adding a noindex mark to a page:
1. WordPress implementation (Using Yoast SEO)
For individual pages:
- Install and activate Yoast SEO
- Open your target page
- Find the Yoast SEO meta box
- Click ‘Advanced’
- Select ‘No’ under ‘Allow search engines to show this Page in search results?’
For Taxonomies and Archives:
Navigate to SEO > Search Appearance in your dashboard. Under the appropriate tab (Taxonomies or Archives), you can control indexing for categories, tags, and author pages.
2. How to set up a robots.txt noindex tag
The other method of marking a page noindex is by using a robots.txt file. This is how you can do it:
Blocking a Single Page:
- Edit your robots.txt file, typically found in your website’s root directory.
- Add the following directive:
User-agent: *
Disallow: /your-page/ - Save and upload the robots.txt file back to your root directory.
Blocking an Entire Directory or Library:
- To block all pages within a directory, add the following directive:
User-agent: *
Disallow: /your-directory/ - Save and upload the updated robots.txt file to the root directory.
Editing the robots.txt file is an effective way to control crawler behavior at scale across your site. Unlike HTML meta tags, which apply on a per-page basis, you can make robots.txt changes and have them affect many pages in short order. For directing crawlers and managing how different parts of your site are indexed, you can’t go wrong using robots.txt.
Noindex vs. other SEO directives
Knowing the difference between noindex and other directives is vital to SEO management, as each directive is a tool with a specific function that must be used correctly to achieve the desired results.
1. Noindex vs nofollow
The noindex and nofollow tags serve distinct purposes in SEO. Noindex prevents pages from appearing in search results, while nofollow instructs search engines not to follow the links on a page. Think of noindex as controlling page visibility and nofollow as managing link authority distribution.
You can combine these tags for pages that need both functions:
<meta name="robots" content="noindex, nofollow">
This combination is particularly useful for pages like transaction confirmations, where you want neither the page indexed nor its links followed.
2. Noindex vs disallow
While similar in purpose, these directives work differently:
- Noindex allows search engines to crawl the page but prevents it from appearing in search results
- Disallow (in robots.txt) blocks search engines from accessing the page entirely
Choose noindex when you want search engines to discover the page through internal links or sitemaps but keep it out of search results. Use disallow when you want to prevent any crawler interaction with the content.
3. Noindex vs canonical
These tags solve different problems:
- Noindex removes pages from search results entirely
- Canonical tags identify the preferred version of similar or duplicate pages
Use canonical tags when you have multiple URLs showing the same content (like product pages with different parameters) and want to consolidate their SEO value. Use noindex when you want to completely remove a page from search results.
Best practices for implementing noindex tags
Noindex tags can significantly impact your SEO performance. Here’s how it’s done:
1. HTML vs. CMS settings
When working with hard-coded websites, you can add noindex tags directly into the HTML. For sites running on CMS platforms like WordPress, Wix, or Shopify, you have the option to modify HTML through website files. However, if you’re not comfortable with code, most CMS platforms offer SEO plugins or built-in SEO settings that make implementation straightforward. This is particularly useful for larger sites where bulk implementation is needed.
Modifying HTML directly gives you granular control over each page and is a good option if you are comfortable with this level of coding. However, if you prefer to avoid writing code (or if you have a larger site), a CMS setting combined with a plugin can be an easier and faster way to go.
2. Test noindex implementations
Verification is essential when implementing noindex tags. Use Google Search Console’s URL Inspection tool to confirm your implementations are working correctly. This helps prevent overshot crawl budgets and ensures important pages remain indexed while confirming all tags are functioning as intended.
3. Don’t use ‘noindex’ on duplicate content
When dealing with duplicate content, canonical tags are generally more effective than noindex. Multiple URLs with identical content can dilute ranking potential, but canonical tags help consolidate link equity to a single URL. This approach maintains a unified presence in search results and ensures optimal search engine performance.
4. ‘noindex’ may lead to ‘nofollow’
Long-term use of noindex can have unintended consequences. Search engines may begin treating the page as nofollow and might ignore outgoing links, impacting your overall link equity distribution. To maintain optimal crawling and indexing capabilities, use the ‘follow’ directive whenever possible. Conduct regular SEO audits of your noindex directives to avoid losing link equity and keep your SEO campaigns on track.
5. Exclude ‘noindex’ pages from your sitemap
Noindex pages are not automatically removed from sitemaps, which can create conflicting signals for search engines. While the noindex tag tells search engines not to display a page in search results, keeping it in the sitemap suggests it’s important for indexing.
To avoid confusion and improve crawling efficiency, it’s best practice to manually remove noindex pages from your sitemap or configure your SEO tools to exclude them. This ensures a clearer, more focused sitemap, helping search engines better understand which pages to prioritize for indexing.
When implementing noindex tags on pages, it’s a best practice to manually remove those pages from your sitemap. Many CMSs and SEO plugins may still include noindex pages in the sitemap by default.
How to check noindex pages
Checking for noindex tags on a regular basis helps keep your SEO strategy clean and efficient. There are many tools and methods to help you verify and audit your noindex installations and keep your technical SEO and SEO strategy up to date, relevant and performing well.
Browser extensions
Browser extensions that check your technical SEO aspects quickly flag noindex tags on pages and provide instant feedback as you browse the site. This makes it easy to monitor and correct your noindex implementations. When used regularly, these extensions help prevent mistakes and ensure pages do not appear in search results when they shouldn’t.
Google Search Console
You can get a comprehensive view ofl your indexed or non-indexed pages when you use Google Search Console for SEO. Through the Coverage report, you can quickly identify which pages are excluded by noindex tags. This dashboard is essential for maintaining your site’s health and allows you to spot and correct errors immediately. To check your noindex pages, simply access the Coverage report in your Search Console account.
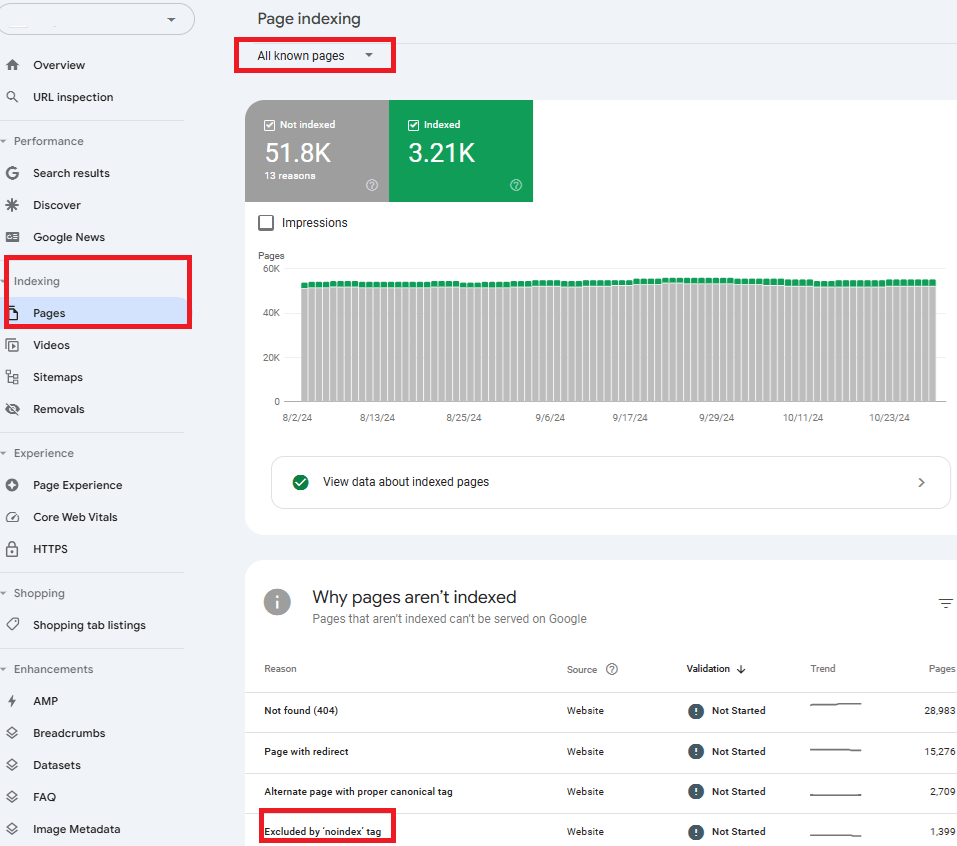
While this approach is useful, it has two main limitations.
First, it only shows pages that Google has already detected, meaning you can fix issues but can’t proactively prevent them, which could increase your workload. Second, in the “All known pages” section, URLs often have parameters (e.g., domain.com/slug/?parameter), resulting in duplicate URLs that differ only by those parameters. This leaves you choosing between incomplete data or data cluttered with parameter duplicates.
Similarweb’s Site Audit tool
Similarweb’s SEO audit tool is an excellent way to identify noindex tags. Via this platform, go to your project and then visit ‘SEO’, ‘Indexability’ and ‘Non-Indexable’ to get the report.
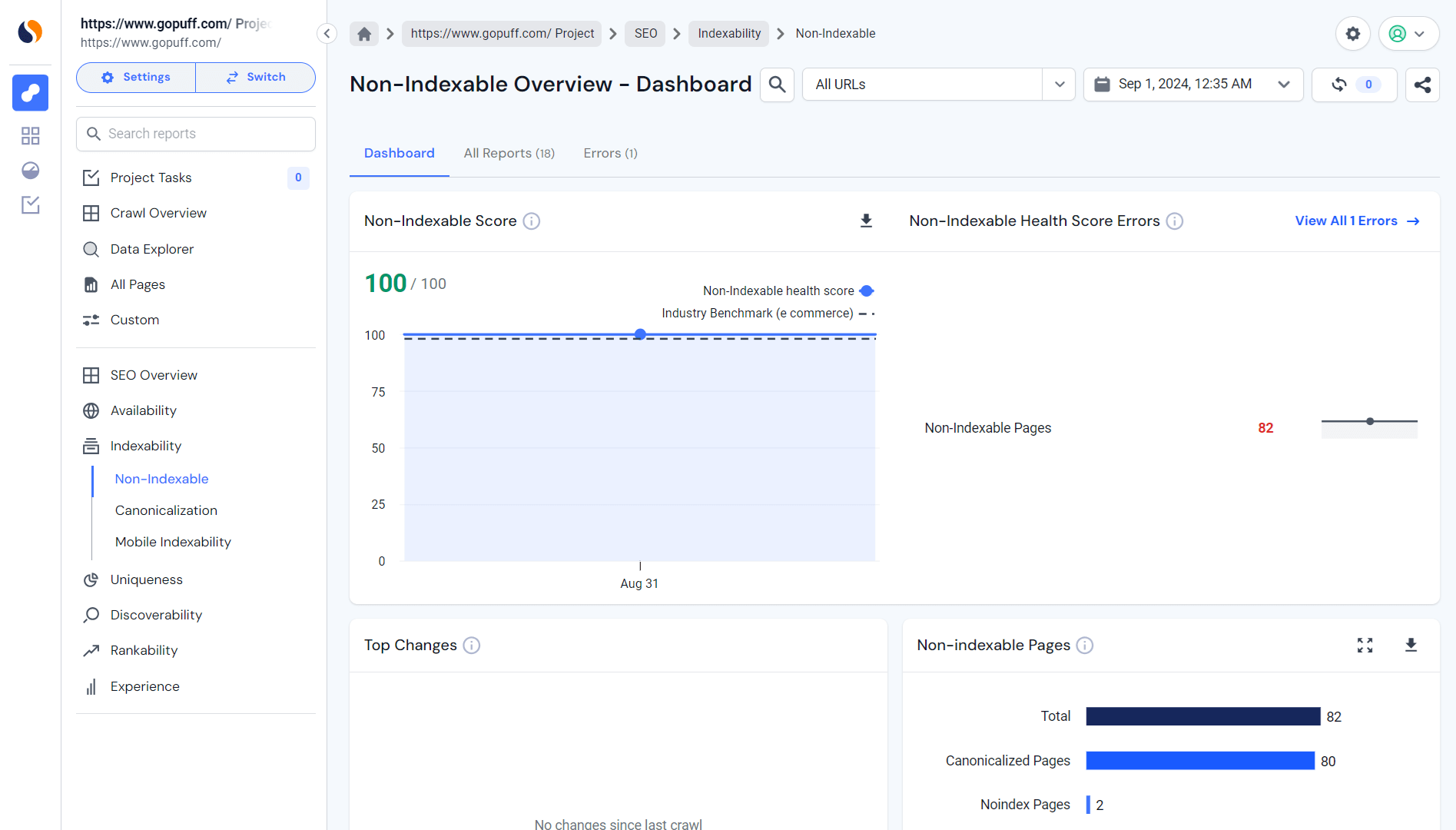
This integrated way of thinking about SEO helps you form a comprehensive strategy with less room for gaps. With the help of Similarweb, every noindex tag is in its rightful place to help your overall SEO health.
Make the noindex tags work for you, not against you
Using the noindex tag wisely can help you to get your SEO skyrocketing in no time at all. First, because it prevents problematic pages from being indexed at all.
Second, because it allows you to make the most of your crawl budget.
And third, because the more you review your noindex implementations, the less accidental dead pages you are likely to have in your index and the your users will be.
Try Similarweb’s Site Audit Tools to keep your site health in check. Sign up for our insights today and jump up the SEO learning curve.
FAQs
What is the noindex tag?
The noindex tag is a directive used to instruct search engines not to include a specific webpage in their search results. By adding this tag to a page, you ensure that it will not appear in search engine rankings, regardless of its URL or any links pointing to it.
When should I use the noindex tag for SEO?
If you want search engines not to include a specific page in their search results, use noindex. This tag will hide your pages if you have content you find to be of low value, private information, or if you’re basing the page off an uninteresting but necessary part of your site, for instance, a terms and agreement page.
Can noindex tags be used for compliance reasons?
Yes, noindex tags can be part of the compliance strategy by keeping confidential or non-published information away from the search results. These tags can be implemented as part of a larger strategy to keep content that shouldn’t be indexed and shown to search engines, visible only to the intended audience.
Are noindex tags relevant for all types of content?
Not every piece of content is a good candidate for noindex tags. Think of them as most appropriate for pages that don’t serve an SEO goal. That could include thank-you pages, page-not-found 404s or internal site search results, as well as pages containing private member content. Noindexing these kinds of pages is a simple way of tidying up site quality without risking major adjustments to existing SEO efforts.
How often should noindex tag audits be conducted?
You should conduct an audit every couple of months, tag all the pages you think you need to, and ensure there are no errors. Reviewing a checklist every month or every quarter can keep your SEO on track, with success metrics that align with your business objectives.

Related Posts


Why AI Engines Cite UGC Over Brand Content And How To Leverage It For AEO

AI Mentions vs. AI Citations: What’s the Difference and Why It Matters for GEO


How to Do A Competitive Analysis: Complete Guide & Free Templates


Track Gen-AI And Organic KPI's On The #1 SEO Platform
Give it a try or talk to our marketing team - it’s free!